Production IT infrastructure for Sofiamed Hospital
Since 2023 we manage the entire IT infrastructure of one of Bulgaria's large private hospitals — an environment where systems can't stop, because behind them are patients, doctors and care.
Transparency note: we only state figures we can confirm. We don't publish invented statistics.
The context
A hospital runs around the clock. Reception, the lab, imaging, the pharmacy and the clinical departments all depend on systems being available — not "most of the time," but continuously. When we took on the engagement, the goal was clear: make the IT environment predictable, documented and resilient, without disrupting day-to-day operations.
The challenges
A real production environment comes with constraints that don't exist in a test lab:
- Zero tolerance for downtime. Maintenance and changes must be planned so they don't affect patient care.
- Many locations, one logic. Separate sites must operate as one secure network, with stable connectivity between them.
- A heterogeneous environment. Windows and Linux servers, different applications and devices that must be managed consistently.
- Sensitive data. Access, security and backups must meet high standards.
- A large number of devices and users. Without order, requests get lost and assets become invisible.
Real responsibilities, every day
This isn't a one-off project. It's the ongoing operation of live infrastructure.
Configuration, updates, monitoring and maintenance of production servers.
Managing the network, segmentation and stable connectivity between sites.
Securely connecting locations into one shared, encrypted network.
Watching availability and performance to catch problems early.
Automated backups with periodic verification of real restores.
A defined process for quickly isolating and restoring service.
A helpdesk for staff — requests, priorities and traceability.
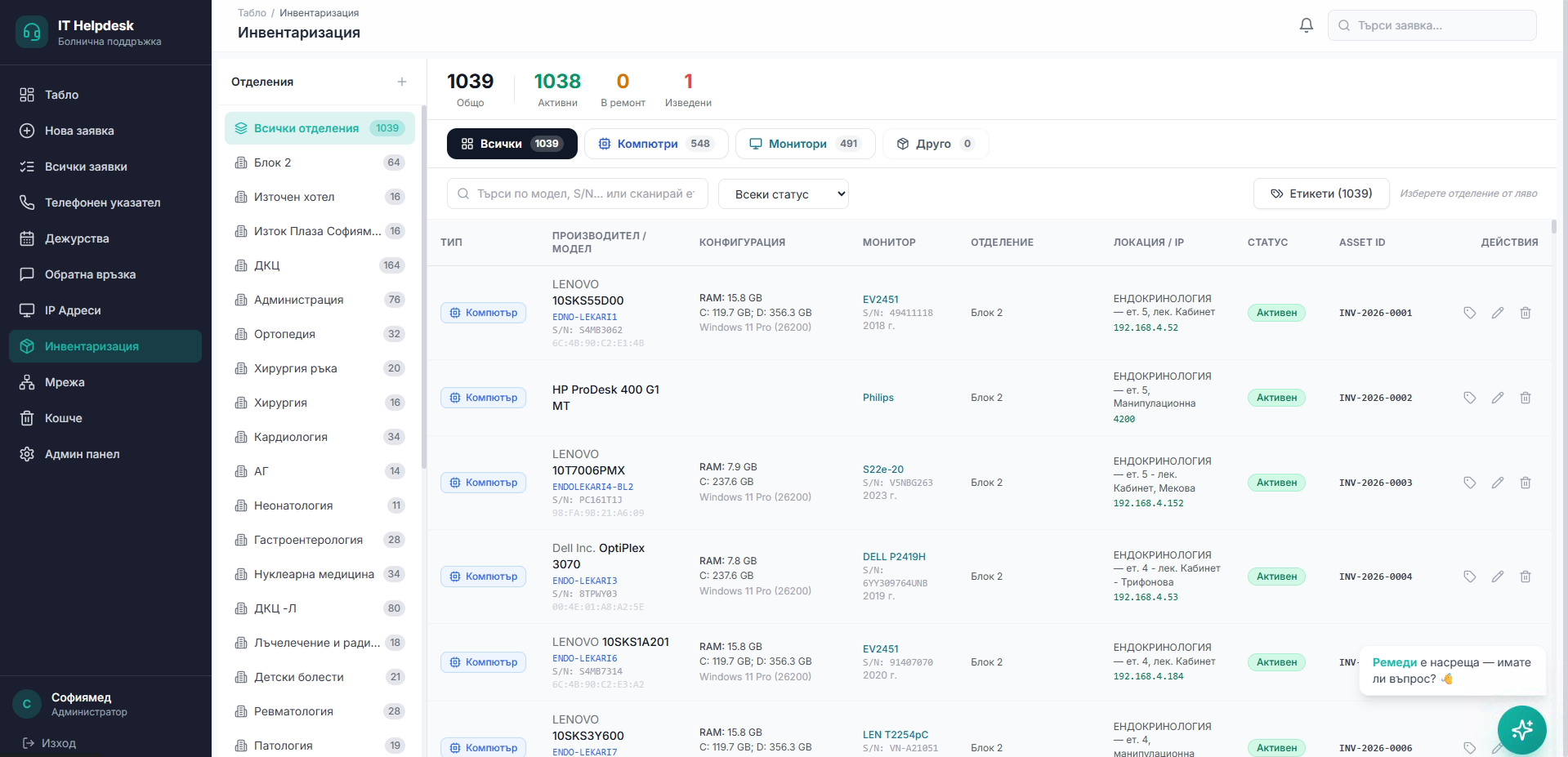
Inventory of 1,039 devices with history and current state.
Maintained documentation of network, servers, access and procedures.
Automating routine tasks to reduce manual work and errors.
Development and maintenance of the helpdesk system described below.
Coordinated management of all sites as one environment.
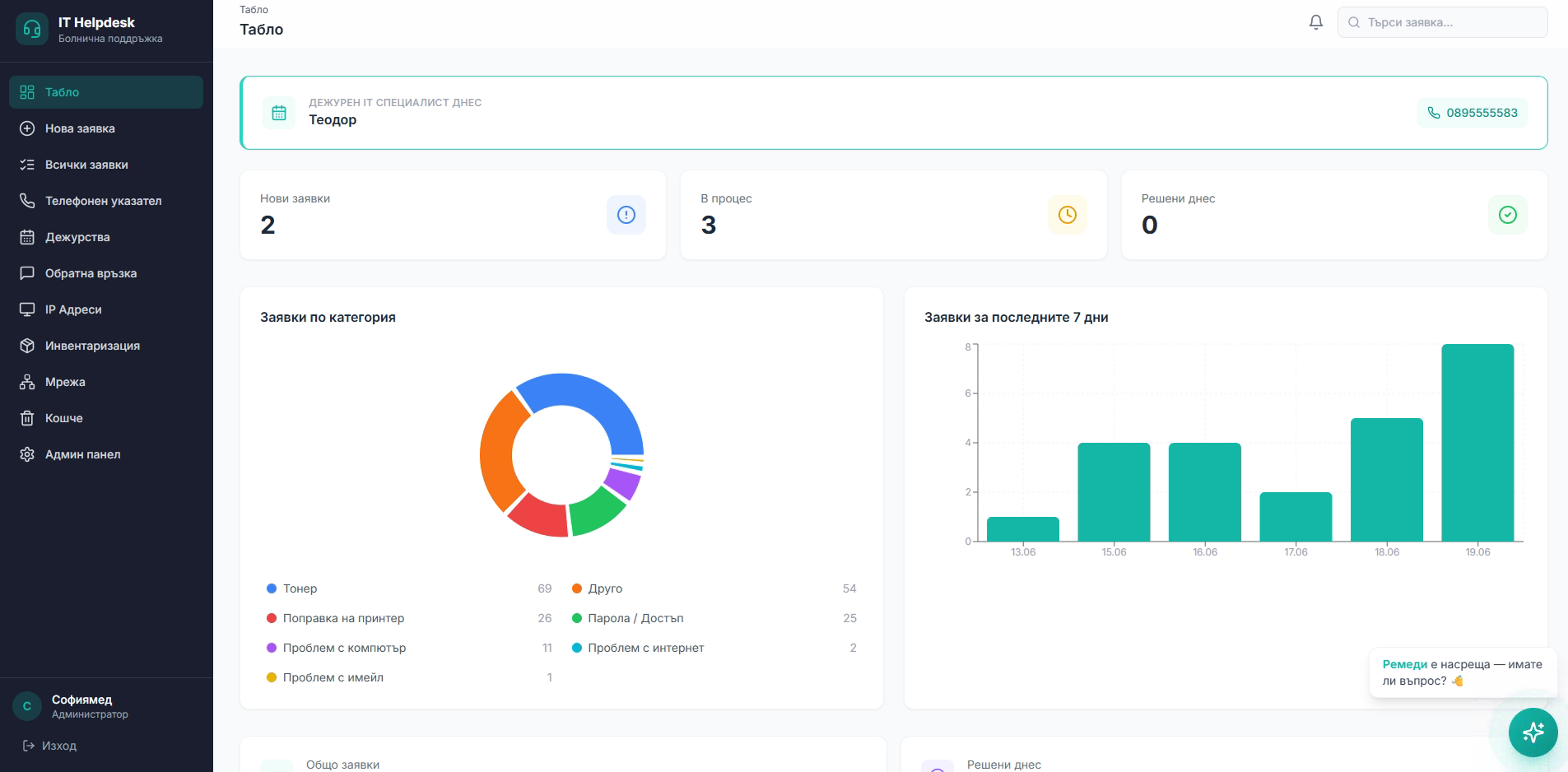
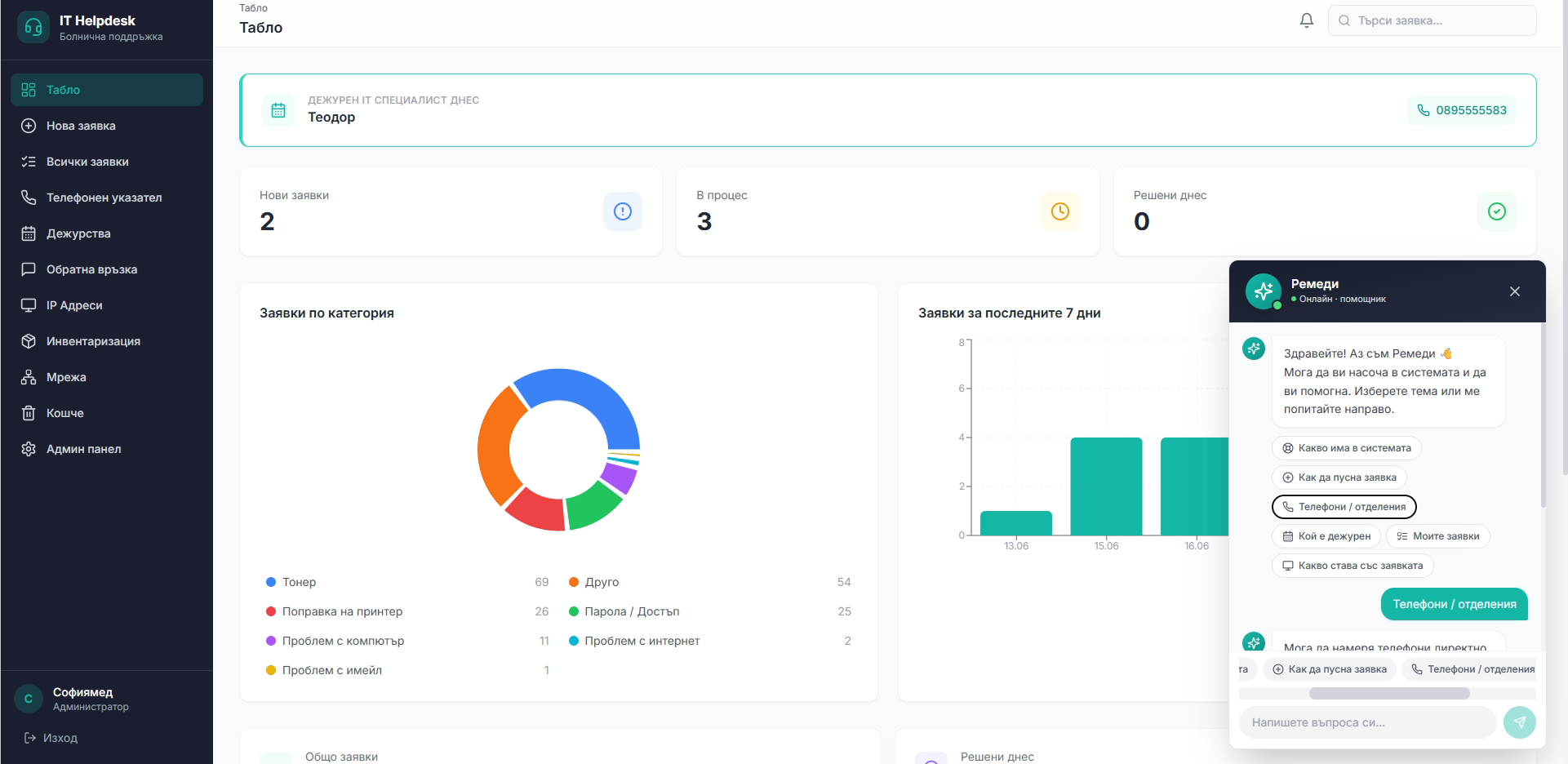
A helpdesk system built around the real process
Off-the-shelf helpdesk products didn't match how the hospital works. So we built our own — for tickets, inventory and on-call scheduling — which we manage and evolve in real use.

All screens use anonymized data. We don't show real names, patient data or sensitive information — even in our own case studies.
Our approach
We started the way we start every engagement — with an audit and mapping, to understand what exists and where the risks are. From there we built up systematically:
Stabilize and order
We bring backups to a state where they actually restore, arrange access along least-privilege, and document the network and servers so knowledge doesn't live in one person's head.
Connectivity between sites
Through site-to-site VPN the locations work as one secure network, and remote access is controlled and encrypted.
Visibility and response
Monitoring and alerting warn us of deviations before they become incidents. When a problem does occur, we follow a defined process for fast restoration and then document what happened.
Order in requests and assets
The custom helpdesk introduced traceability — requests no longer get lost in emails, and 1,039 devices have history and current state in one place.
Illustrative schematic. Real addresses, names and segment counts are anonymized — exactly as we anonymize data in our own case studies.
What changed
Qualitative impact, described honestly — without attributing invented numbers.
Predictability
The infrastructure runs quietly and stably. Problems are caught early through monitoring instead of surprising anyone.
Transparency
A documented environment and traceable requests make it clear who does what and the state of everything.
Lower risk
Verified backups, controlled access and a segmented network reduce the risk of data loss and downtime.
We manage critical infrastructure. We can take on yours too.
We start with an audit and clear priorities — no obligation.